PostgreSQL から RESTful API を自動で生成する
この記事は 株式会社オプティマインド による「Optimind Advent Calendar 2024」の 16 日目の記事です。
はじめに
PostgREST は PostgreSQL のデータモデル(デーブルやビューなど)から直接 API エンドポイントを生成し、RESTful API によってデータベースを操作することを可能にした API サーバーです。最近注目を集めている Supabase のデータ API も実は PostgREST で構成されているのです。
この記事では、PostgREST の基本操作と私がピックアップした 3 つの機能を実際に試しながら紹介していきたいと思います。
環境準備
素早く環境が立ち上げられるよう、軽量な Docker Compose 構成を用意しました。
# リポジトリのクローン
git clone https://github.com/bohanwood/postgrest-playground.git
# 環境の立ち上げ
docker compose up -d
構成部品とアクセス方法は以下です。
- Supabase Studio
- http://localhost:9090/
- Web GUI でデータを操作できます(DB 以外の Supabase コンポーネントは使えません)
- Swagger UI
- http://localhost:9090/swagger/
- PostgREST 自動生成の OpenAPI ドキュメントが表示されます
- PostgREST
- PostgreSQL
テストデータのインポート
neondatabase-labs/postgres-sample-dbs にある chinook を使用します。
wget https://raw.githubusercontent.com/neondatabase/postgres-sample-dbs/main/chinook.sql
# SQL ファイルを読み込む
docker compose exec -T postgres psql < chinook.sql
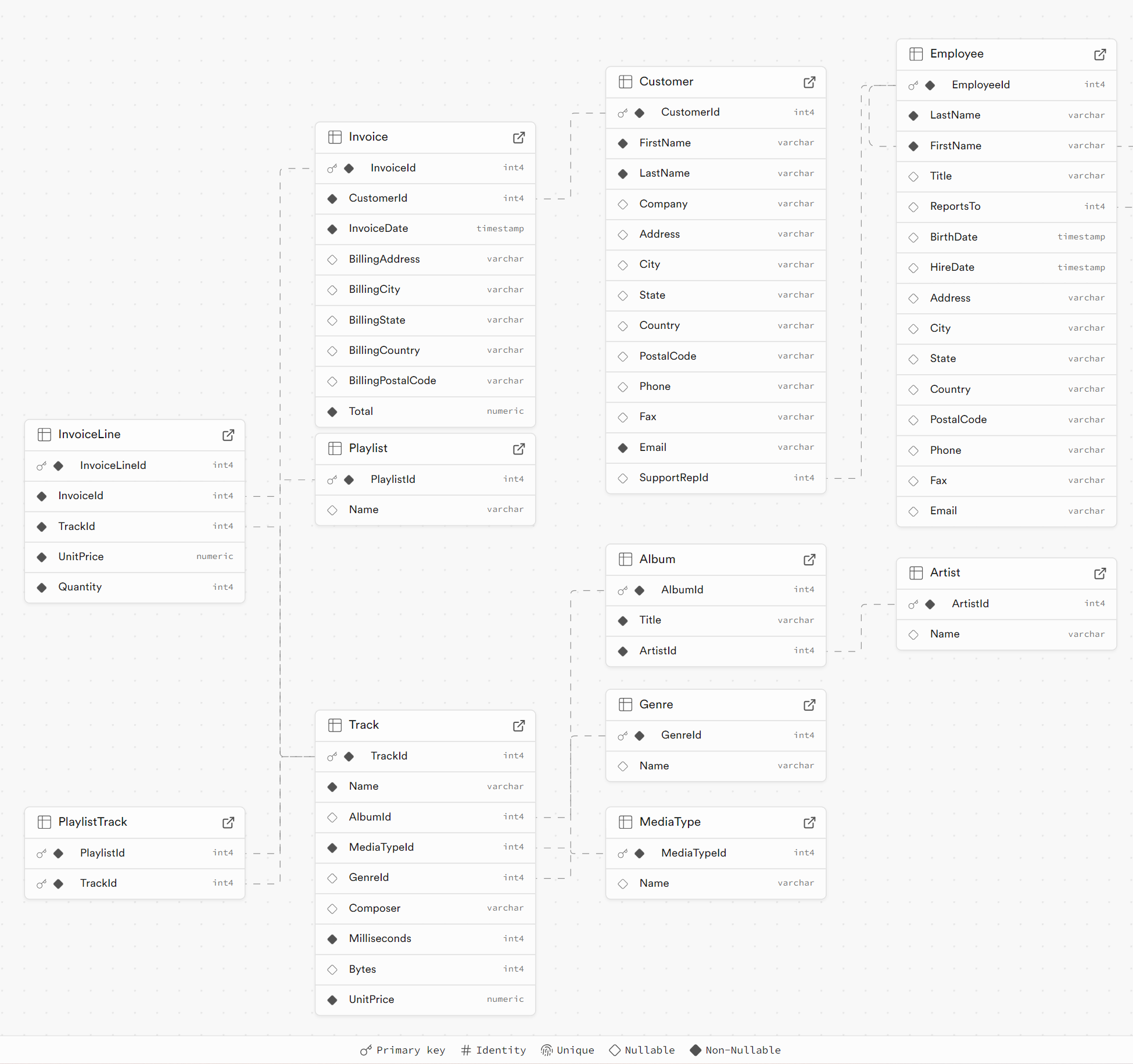
その後、Supabase Studio で自動生成された ER 図を確認できます。
http://localhost:9090/project/default/database/schemas
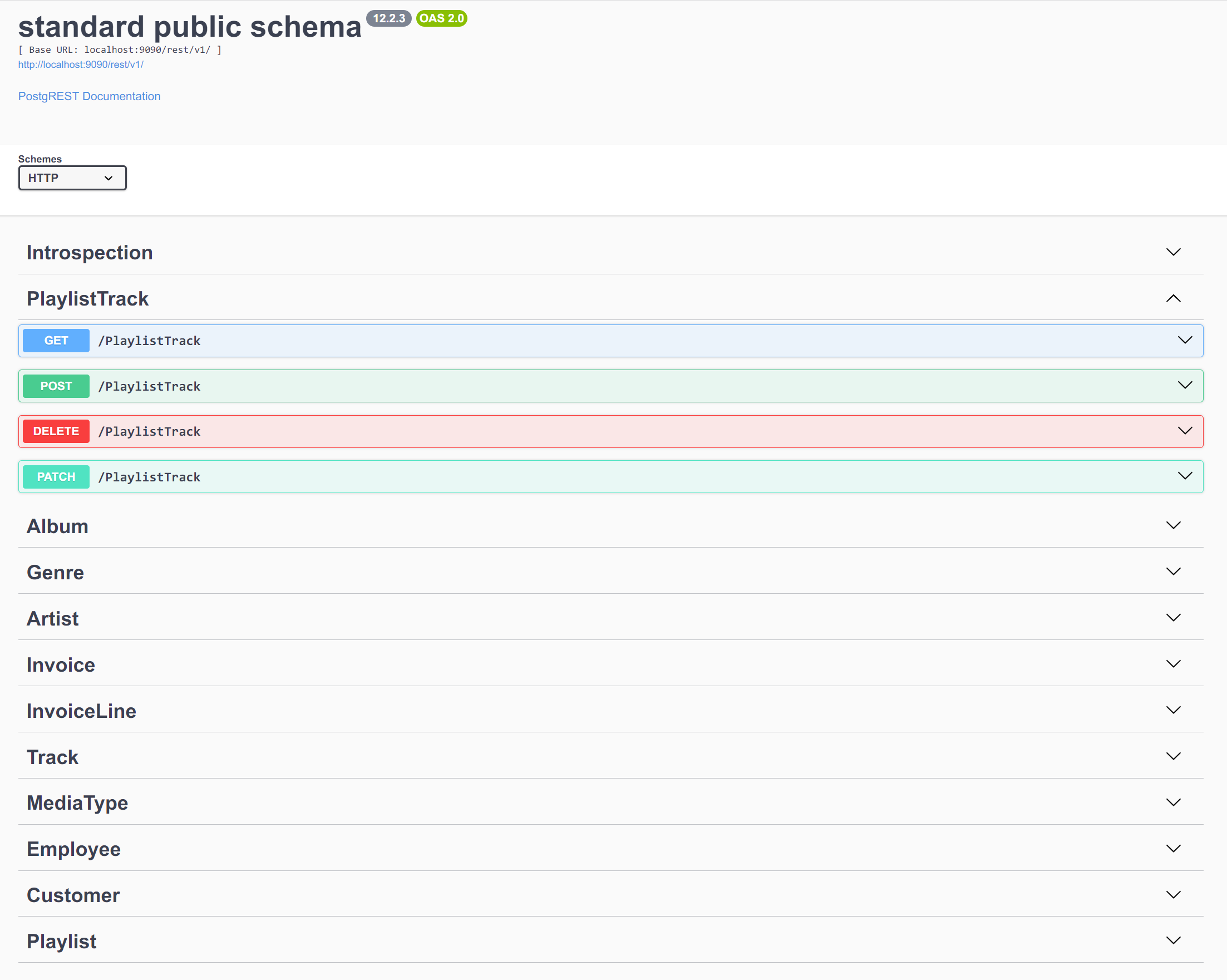
また、Swagger UI で自動生成された OpenAPI ドキュメントを確認できます。
http://localhost:9090/swagger/
PostgREST の基本操作
では、PostgREST のを試してみます。
GET - データの検索
- Swagger UI で GET /Customer のエンドポイントでクエリを以下のように指定します
- Country: eq.France
- select: FirstName, LastName, Email
- order: CustomerId.desc
- limit: 3
これで住所がフランスのお客様を、CustomerId 降順で並び替え、カラムは苗字、名前、メールアドレスのみで、3件取得できました。
curl -X 'GET' \
'http://localhost:9090/rest/v1/Customer?Country=eq.France&select=FirstName%2C%20LastName%2C%20Email&order=CustomerId.desc&limit=3' \
-H 'accept: application/json'
[
{
"FirstName": "Isabelle",
"LastName": "Mercier",
"Email": "isabelle_mercier@apple.fr"
},
{
"FirstName": "Wyatt",
"LastName": "Girard",
"Email": "wyatt.girard@yahoo.fr"
},
{
"FirstName": "Marc",
"LastName": "Dubois",
"Email": "marc.dubois@hotmail.com"
}
]
POST - リソースの新規作成
curl -X 'POST' \
'http://localhost:9090/rest/v1/Artist' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"ArtistId": 444,
"Name": "Brian Kernighan"
}'
Tips:デフォルト値をリクエストボディから省きたい場合は(シーケンスなどを利用して ArtistId を生成している場合など)、ヘッダーに Prefer: missing=default を指定すれば良いです。
https://docs.postgrest.org/en/v12/references/api/tables_views.html#bulk-insert-default
PATCH - リソースの更新
ArtistId が 444 と 222(ArtistId=in.(444,222))の Artist の名前を Shen Lin に変更し、変更後のリソースを返します(Prefer: return=representationが指定されているため)。
curl -X 'PATCH' \
'http://localhost:9090/rest/v1/Artist?ArtistId=in.(444%2C222)' \
-H 'accept: application/json' \
-H 'Prefer: return=representation' \
-H 'Content-Type: application/json' \
-d '{
"Name": "Shen Lin"
}'
DELETE - リソースの削除
ArtistId が 444 の Artist を削除し、削除されたデータを返します(Prefer: return=representationが指定されているため)。
curl -X 'DELETE' \
'http://localhost:9090/rest/v1/Artist?ArtistId=eq.444' \
-H 'accept: application/json' \
-H 'Prefer: return=representation'
特に削除されたデータを DELETE のリスポンスで返せるという点は、活用できるユースケースは多くあるかと思います。
Return Presentation については以下のドキュメントに記載されています。
https://docs.postgrest.org/en/v12/references/api/preferences.html#return-representation
関連リソースの埋め込み(Resource Embedding)
- Swagger UI で GET /Invoice のエンドポイントでクエリを以下のように指定します
- select:
*, InvoiceLine(*, Track(*, Album(*, Artist(*)))), Customer(*) - limit: 1
- select:
(少し大げさな例ではありますが)このようにselect にカラム名のほか、外部キーが設定されているテーブル名を指定することで、
- Invoice → InvoiceLine:一対多
- InvoiceLine → Track → Album → Artist:多対一
- Invoice → Customer:多対一
のリレーションシップで関連しているリソースを一つのリクエストで取得できました。
この Resource Embedding という機能は GraphQL と似ている気もしますね。公式ドキュメントはこちらになります。
https://docs.postgrest.org/en/v12/references/api/resource_embedding.html
[
{
"InvoiceId": 1,
"CustomerId": 2,
"InvoiceDate": "2009-01-01T00:00:00",
"BillingAddress": "Theodor-Heuss-Stra�e 34",
"BillingCity": "Stuttgart",
"BillingState": null,
"BillingCountry": "Germany",
"BillingPostalCode": "70174",
"Total": 1.98,
"InvoiceLine": [
{
"Track": {
"Name": "Balls to the Wall",
"Album": {
"Title": "Balls to the Wall",
"Artist": {
"Name": "Accept",
"ArtistId": 2
},
"AlbumId": 2,
"ArtistId": 2
},
"Bytes": 5510424,
"AlbumId": 2,
"GenreId": 1,
"TrackId": 2,
"Composer": null,
"UnitPrice": 0.99,
"MediaTypeId": 2,
"Milliseconds": 342562
},
"TrackId": 2,
"Quantity": 1,
"InvoiceId": 1,
"UnitPrice": 0.99,
"InvoiceLineId": 1
},
...
],
"Customer": {
"Fax": null,
"City": "Stuttgart",
"Email": "leonekohler@surfeu.de",
"Phone": "+49 0711 2842222",
"State": null,
"Address": "Theodor-Heuss-Stra�e 34",
"Company": null,
"Country": "Germany",
"LastName": "K�hler",
"FirstName": "Leonie",
"CustomerId": 2,
"PostalCode": "70174",
"SupportRepId": 5
}
}
]
Upsert 操作
以下のように、ArtistId 555 と 222 を新規作成してみます。
curl -X 'POST' \
'http://localhost:9090/rest/v1/Artist' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '[
{
"ArtistId": 555,
"Name": "PostgreSQL Elephant"
},
{
"ArtistId": 222,
"Name": "PHP Elephant"
}
]'
この時に、222 が既に存在しているため、ユニーク制約に制限されます。
{
"code": "23505",
"details": "Key (\"ArtistId\")=(222) already exists.",
"hint": null,
"message": "duplicate key value violates unique constraint \"PK_Artist\""
}
新規に対しては INSERT で、既存に対しては UPDATE、という概念が UPSERT です。この操作は PostgREST では Prefer: resolution=merge-duplicates というヘッダーを指定することで行えます。
curl -X 'POST' \
'http://localhost:9090/rest/v1/Artist' \
-H 'accept: application/json' \
-H 'Prefer: resolution=merge-duplicates' \
-H 'Content-Type: application/json' \
-d '[
{
"ArtistId": 555,
"Name": "PostgreSQL Elephant"
},
{
"ArtistId": 222,
"Name": "PHP Elephant"
}
]'
これで、ArtistId 555 が新規作成され、既存の ArtistId 222 が更新されました。
Upsert の利用シーン
どのような時に Upsert が活用されるか、イメージがしづらいかもしれません。
例えば、PC で実行されている各アプリケーションのデータ転送量を、一定時間おきに PostgREST を叩いて、DB に最新の数字をアップロードするプログラムがあります。
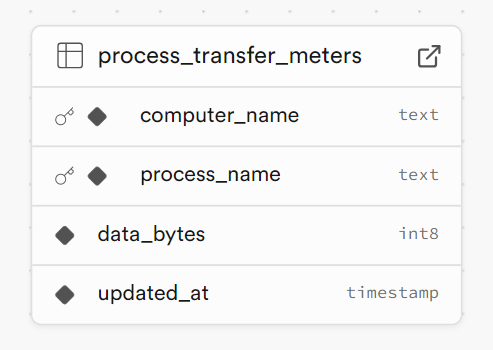
curl -X 'POST' \
'http://localhost:9090/rest/v1/process_transfer_meters' \
-H 'accept: application/json' \
-H 'Prefer: resolution=merge-duplicates' \
-H 'Content-Type: application/json' \
-d '[
{
"computer_name": "PC001",
"process_name": "GIMP",
"data_bytes": 123456,
"updated_at": "2006-01-02T15:04:05Z"
},
{
"computer_name": "PC001",
"process_name": "Firefox",
"data_bytes": 234567,
"updated_at": "2006-01-02T15:04:05Z"
}
]'
computer_name と process_name が複合キーとして設定されています。
一台の PC にたくさんのアプリが実行されており、また常に新しいアプリがインストールされます。
computer_name は変わらないのですが、Upsert がない場合、その process_name が新しいものか既存のものかで区別するのと、少なくとも 2 回のリクエスト(POST と PATCH)が必要になります。
Upsert を利用することで、新しいものか既存のものかを区別する手間なく、常に 1 回のリクエストで済むようになります。
JWT による認証と行セキュリティポリシー
PostgREST の認証では JWT の Bearer Token が使われています。JWT ペイロードの role フィールドで、特定の PostgreSQL のロールを(このリクエストに限り)適用するような使い方ができます。
このような PostgREST の機能を使った運用として、Supabase ではデフォルトで以下の PostgreSQL のロールが用意されています。
- anon - ゲストユーザー(未ログイン)
- authenticated - ログインしたユーザー
- service_role - 管理者
これらの PostgreSQL のロール、また JWT ペイロードにある sub などのフィールドを PostgreSQL 行セキュリティポリシーに指定することでアクセス制御ができるようになります。
それでは実際に試してみましょう。
行セキュリティポリシーの設定
以下のように、Invoice テーブルに対して、PostgreSQL の行セキュリティを有効にして、行セキュリティポリシーを設定します。
- CLI -
docker compose exec postgres psql - GUI (Supabase Studio)
alter table "Invoice" enable row level security;
-- 管理者にすべての操作を許可する
create policy "invoice_admin_allow_all" on "public"."Invoice" as permissive for all to service_role using (true);
-- ログインしたユーザーに自分のインボイスの閲覧を許可する
create policy "invoice_allow_select_owned" on "public"."Invoice" as permissive for select to authenticated
using ((select current_setting('request.jwt.claims', true)::json->>'sub') = "CustomerId"::text);
これで未ログインのユーザーは Invoice の閲覧ができなくなります(空配列が返されます)。
curl -X 'GET' \
'http://localhost:9090/rest/v1/Invoice' \
-H 'accept: application/json'
ログインしたユーザーが自身の Invoice を閲覧できる
ログインしたユーザーを模擬するため、JWTを生成する必要があります。
ここでは https://jwt.io/ を使用します。
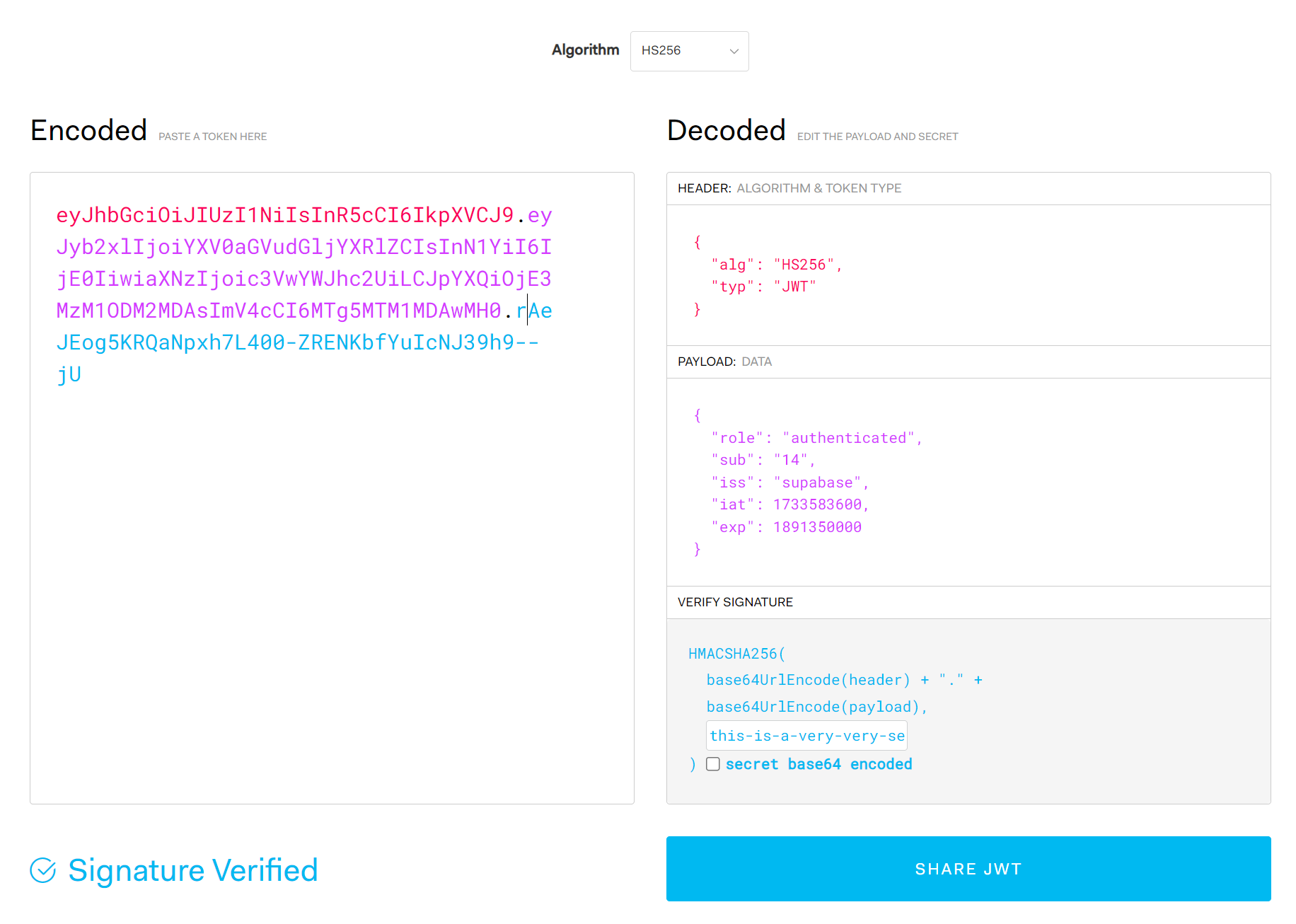
.env から JWT_SECRET を取得し、ペーストします。続いてペイロードを以下のように変更します。
{
"role": "authenticated",
"sub": "14",
"iss": "supabase",
"iat": 1733583600,
"exp": 1891350000
}
これに Bearer をつけて Authorization ヘッダーに入れることで、ID 14 のユーザーがログインした状態を模擬できます。
curl -X 'GET' \
'http://localhost:9090/rest/v1/Invoice?limit=10' \
-H 'accept: application/json' \
-H 'Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJyb2xlIjoiYXV0aGVudGljYXRlZCIsInN1YiI6IjE0IiwiaXNzIjoic3VwYWJhc2UiLCJpYXQiOjE3MzM1ODM2MDAsImV4cCI6MTg5MTM1MDAwMH0.rAeJEog5KRQaNpxh7L400-ZRENKbfYuIcNJ39h9--jU'
Swagger UI では「Authorize」のダイアログで設定できます。
これで、ログインしたユーザー(JWT ペイロードの sub が 14)が自身の Invoice(CustomerId が 14 の Invoice)を閲覧できることを確認しました。
[
{
"InvoiceId": 4,
"CustomerId": 14,
"InvoiceDate": "2009-01-06T00:00:00",
"BillingAddress": "8210 111 ST NW",
"BillingCity": "Edmonton",
"BillingState": "AB",
"BillingCountry": "Canada",
"BillingPostalCode": "T6G 2C7",
"Total": 8.91
},
{
"InvoiceId": 133,
"CustomerId": 14,
"InvoiceDate": "2010-08-13T00:00:00",
"BillingAddress": "8210 111 ST NW",
"BillingCity": "Edmonton",
"BillingState": "AB",
"BillingCountry": "Canada",
"BillingPostalCode": "T6G 2C7",
"Total": 1.98
},
...
]
管理者が全ての Invoice を閲覧できる
JWT のペイロード以下のように変更し、生成された Bearer Token で再度リクエストします。
{
"role": "service_role",
"iss": "supabase",
"iat": 1733583600,
"exp": 1891350000
}
curl -X 'GET' \
'http://localhost:9090/rest/v1/Invoice?limit=10' \
-H 'accept: application/json' \
-H 'Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJyb2xlIjoic2VydmljZV9yb2xlIiwiaXNzIjoic3VwYWJhc2UiLCJpYXQiOjE3MzM1ODM2MDAsImV4cCI6MTg5MTM1MDAwMH0.YAArBAqpWXEFMEbGKrK1UK94T9JDh7bz-Voy-hwgYm0'
PostgreSQL の service_role が適用されたことで、全ての Invoice を閲覧できることを確認しました。
(Optional)今回の検証環境と Supabase との違い
今回試してきた PostgREST 環境はあくまでも独自の検証環境であり、Supabase と少し異なる点がございます。
Supabase では、以下の API キー・トークンが同時に必要です。
- Bearer Token
- JWT Secret でサインされていれば OK
- PostgREST(または他のコンポーネント)によって読み込まれる
ApiKeyヘッダーまたはクエリパラメータ**(今回の検証環境では使われなかった)**- 付与された API Key(anon と service_role キー)
- 特定の文字列でなければならない**(それがたまたま JWT であるだけ)**
- API Gateway のアクセス制御で使われるが、その裏にある PostgREST 等には使われない
Supabase のこちらの仕組みは良い設計になっているとは中々言えず、新しい仕組みへの移行が予定されています(Q4 2024)。
https://github.com/orgs/supabase/discussions/29260
最後に
私が PostgREST を使おうと思ったのは、「必要なデータを必要なフォーマットに変換する」という SQL が得意とする作業をよりデータに距離が近い DB 側が行うことで、アプリケーションコードの簡素化や性能の向上が期待できるためです。
ただ、実際に複雑なアプリケーションを PostgreSQL+PostgREST や Supabase で構築する際、難しい点が数多くあるかと思います。ビジネスロジックを(アプリケーション側ではなく)ある程度 DB 側に組み込むことになるので、PostgreSQL への深い理解がないままで設計されたスキーマや SQL 関数が、性能の問題やセキュリティリスクにつながりかねません。
とはいえ、PostgreSQL の知識をしっかり把握した上で、その豊富な機能を活用すれば、高速かつシンプルに要件を実装できるので、活躍できるユースケースも大いにあるかと思います。
例えば、最近、Supabase を利用して、個人で運用しているプロキシサーバーの接続情報を管理する DB と、その接続情報からサーバーとクライアントの JSON 設定ファイルを生成する API を構築しました。
テーブルを作成し、ChatGPT を活用してクライアントの JSON 設定ファイルを生成する SQL 関数を書いてもらって DB に追加すると、その関数を呼び出す /rest/v1/rpc/my_sql_function のような API エンドポイントが自動でできて、このようなシーンでは非常に便利なツールだと思います。